Transformatoren wie GPT-3, BERT und T5
Wenn Du nur einen Hammer als Werkzeug hast, dann wirst du jedes Werkstück, wie einen Nagel behandeln. Das klingt jetzt nicht sonderlich effizient, wenn zum Beispiel ein Ei, wie ein Nagel behandelt wird, dann wird das sehr wahrscheinlich nicht das erwünschte Ergebnis bringen. Ausser man findet eine Möglichkeit das Ei in einen Nagel umzuwandeln. Das Werkzeug, um aus dem Ei einen Nagel zu machen nennt man Transformator.
Worum geht es?
Es geht hier darum einen kurzen Überblick, über maschinelles Lernen und im speziellen um die Umsetzung von natursprachlichen Formulierungen in maschinenlesbaren, -interpretierbaren, Code. Es gibt auch konkrete Anwendungsbeispiele, wie AlphaFold 2 – aus genetischen Sequenzen werden Strukturen von Proteinen vorhergesagt. (Anm.: So in etwa habe ich es verstanden) Hier möchte ich mich aber vor allem auf GPT-3, BERT und T5 einlassen. Es handelt sich dabei um Natural Language Processing (vgl.: NLP) Modell, um maschinenlesbaren Code zu produzieren.
Wie funktionieren Transformatoren?
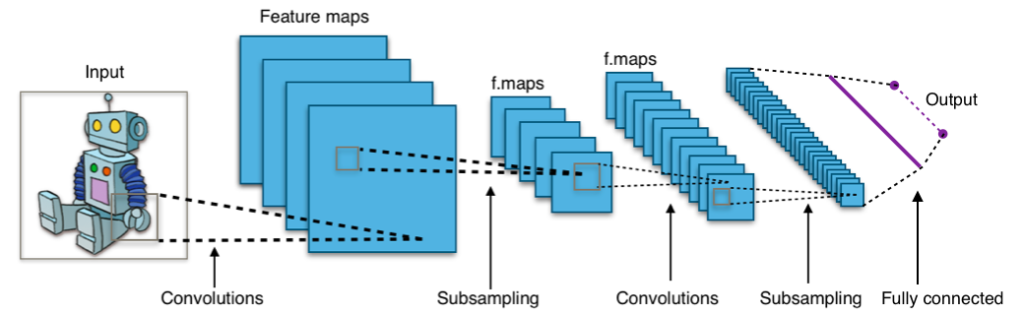
Ein Transformator ist eine Art neuronale Netzwerkarchitektur. Eine gesamtheitliche Sicht und Beschreibung über mehrere Systeme und Komponenten hinweg, um eine nachvollziehbare und steuerbare Struktur zu schaffen. Solche Arten von (komplexen) Strukturen entsprechen neuronalen Netzen. Neuronale Netze sind eine hoch effektive Art von Struktur, um komplexe Datentypen zu analysieren. Komplexe Datentypen sind zum Beispiel Bilder, Videos, Audio und Text. Um bei der Analogie von Hammer und Nagel zu bleiben. Es gibt verschiedene Nagelgrößen und -arten, genauso gibt es auch verschiedene Arten von neuronalen Netzen. Die Art des neuronalen Netzes orientiert sich dem zu untersuchenden Datenobjekt. Entsprechend gibt es verschiedene Optimierungsmodelle, wie konvolutionäre neuronale Netze (vgl.: convolutional neural networks – CNN). Solche CNNs ahmen die Art und Weise nach, wie wir als Mensch visuelle Informationen verarbeiten.
Seit etwa 2010 gibt es erfolgreiche Lösungen von visuellen Problemen mittels CNNs. Damit ist gemeint, das Objekte erkannt werden können. Objekte in Fotos, aber auch das Erkennen von Gesichtern und handschriftliche Objekte. Sprachaufgaben, wie Übersetzungen, Textzusammenfassung, Textgenerierung, Erkennung bekannter Entitäten vor allem, waren bis vor kurzen nicht auf dem selben qualitativen Niveau, wie Gesichtserkennung und Konsorten. Sprache ist aber für uns Menschen der Hauptträger von Kommunikation.
Was war vor den Transformatoren?
Transformatoren werden seit 2017 verwendet. Davor wurde Deep Learning eingesetzt, um Text zu verstehen, mit einem Modell namens wiederkehrendes neuronales Netzwerk (vgl.: Recurrent Neural Network – RNN)
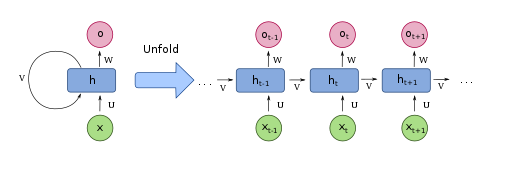
Um wieder bei der Analogie von Hammer und Nagel zu bleiben, nehmen wir für jede Sprache ein eigenes Brett und die Übersetzung erfolgt mit Hammer und Nagel. Der Ort, die Position und Reihenfolge, des jeweiligen Wortes in der Quellsprache – erstes Brett – entspricht dem selben Ort in der Zielsprache – zweites Brett. Wichtig ist auch noch anzumerken, dass dieses Modell ein sequenzielles ist. Also nur immer ein Schritt gleichzeitig möglich. Das macht man vor allem, weil in der Sprache der Gehalt und Inhalt von sprachlichen Mitteln abhängig ist und von ihrer textuellen Platzierung. Das große Problem lässt sich erahnen, es war die Größe an Kontextinformationen, die vorgehalten werden musste, um Zusammenhänge zumindest in logischen Einheiten, wie Absätzen, aufzulösen. Dazu gehört hier das Problem von explodierenden, oder verschwindenden, Gradienten in Zeitreihen. Vor allem aber sind RNNs schwer bis eigentlich gar nicht parallelisierbar.
Wer hat’s erfunden?
Wie schon oben angemerkt, 2017 wurden von Forschern bei Google und der Universität von Toronto das Konstrukt der Transformatoren entwickelt. Der ursprüngliche Zweck ist für Übersetzung entworfen worden. Im Gegensatz zu RNNs können Transformatoren sehr stark parallelisiert werden. Damit können und werden großen Mengen Text als Trainingsbasis verwendbar.
GPT-3 ist ein Textgenerierungsmodell. Dieses kann zum Beispiel Werbemailtexte erstellen, die von menschlich verfassten Individualnachrichten fast nicht mehr zu unterscheiden sind. Als Trainingsdaten für GPT-3 wurden etwa 45 TB an Textdateien – in etwa das gesamte öffentliche Internet – herangezogen.
Wie funktionieren Transformatoren?
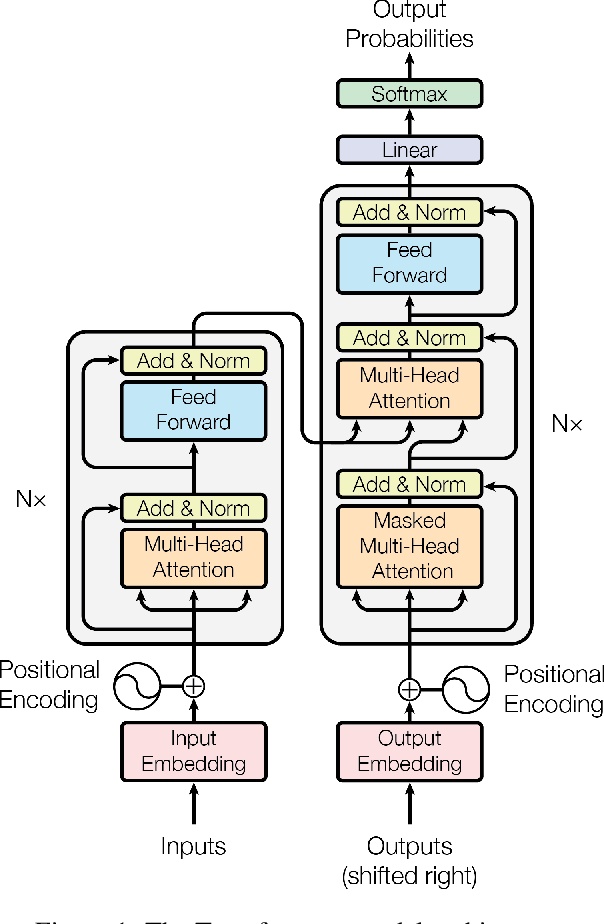
In der eigentlichen Publikation, aus der die obige Grafik stammt, ist das Modell sehr detailliert beschrieben. Mann kann es vielleicht zusammenfassen in drei Bereiche, die unabhängig voneinander untersucht werden.
- Positionserkennung
- Aufmerksamkeit
- Selbstaufmerksamkeit
Was ist Positionserkennung?
Um es kurz zu machen. Die Wortfolge wird als Tupel an sich gespeichert und nicht als Strukturinformation. Ergebnis ist, dass neuronale Netzwerke einfacher zu trainieren sind.
Wenn wir einen Text vom Englischen in das Deutsche mit künstlicher Intelligenz übersetzen wollen, dann haben wir zwei Alternativen. Verwendung von RNN und Transformatoren. Setzen wir auf ein RNN, dann werden die Wörter nacheinander in einer strikten Reihenfolge verarbeitet. Der Kontext wird jedes Mal neu aufgebaut und erstellt. Sprich mit jedem Wort gibt es einen weiteren Kontexteintrag. Das ist auch der Punkt, warum eine Parallelisierung schwierig bis gar unmöglich ist und der Speicher übergeht.
Transformatoren lösen dieses Problem auf indem zu dem jeweiligen Wort eine Positionskodierung mitgeführt wird. Wörtern werden anhand ihrer Eingabesequenz eine Zahl – ihre Reihung – mitgegeben. So ein Transformator ist ein in etwa so etwas wie ein Index einer relationalen Datenbank.
Damit wird die Last des Verständnisses der Wortfolge vom neuronalen Netz auf die Daten selbst verschoben.
Der Transformator weiss am Anfang nicht, wie er diese Positionskodierungen interpretieren soll, bevor er für die Daten trainiert wird. Aber da das Modell immer mehr Beispiele für Sätze und ihre Kodierung sieht, lernt es, sie effektiv zu nutzen.
Aber Achtung, das ist eine sehr vereinfachte Darstellung und das heisst auch vor allem Verkürzung. Mit der Verkürzung gehen aber auch leider wertvolle Informationen unweigerlich verloren. Ergo keine Gewähr auf Vollständigkeit und Richtigkeit, sondern Verweis auf den Originalartikel.
Was ist Aufmerksamkeit?
DER NÄCHSTE WICHTIGE TEIL VON TRANSFORMATOREN WIRD AUFMERKSAMKEIT GENANNT.
Verstanden?
Mit dem Großschreiben habe ich die Aufmerksamkeit erzielt. Aufmerksamkeit ist eine neuronale Netzwerkstruktur, von der sie im maschinellen Lernen immer wieder hören werden. Tatsächlich war der Titel der Publikation 2017, mit dem Transformatoren eingeführt wurden, nicht Transformatoren für alle, sondern Aufmerksamkeit ist alles, was sie brauchen. (Vgl.: Attention is all you need)
Wofür brauchen wir jetzt die Aufmerksamkeit bei der Übersetzung? Wir brauchen sie vor allem, um die sprachlichen Eigenheiten im Kontext aufzulösen. In romanischen Sprachen gibt es geschlechtsspezifische Formen von Wörtern. Im Deutschen geht es sogar noch ein bisschen weiter. Im Französischen heisst es, Madame, le professeur, im Deutschen ist es aber die Frau Professorin. Dementsprechend sind die Eigenschaftswörter unterschiedlich bezüglich der geschlechtsspezifischen Beugung. In dem Fall würde im Französischen ein Adjektiv auf die männliche Form (vgl.: le professeur) gebeugt, aber im Deutschen auf die weibliche Form (vgl.: die Professorin). Es gibt aber auch Sprachen, wo diese Informationen rein aus dem Kontext ergeben und sprachlich gar nicht abgebildet werden. Das ist zum Beispiel im Ungarischen der Fall.
Um mit diesen Fällen umgehen zu können haben die Forscher eine Art Heatmap entwickelt, um Positionsverschiebungen abbilden zu können. Die Wahrscheinlichkeit der Verortung, Stellung, eines Wortes im Satz zwischen Quelle und Ziel.
Woher weiss jetzt der Transformator, wie er welche Wörter jetzt anpassen soll? Ganz klar aus seinen Trainingsdaten, die er vor allem im öffentlichen Internet gefunden hat. Daraus hat der Transformator gelernt wie Sätze in verschiedenen Sprachen strukturiert sind. Welche Arten von Wörtern voneinander abhängig sind, wie in der jeweiligen Sprache Geschlecht, Pluralität und andere Grammatikregeln abgebildet sind.
Der Aufmerksamkeitsmechanismus ist seit seiner Entdeckung im Jahr 2015 ein äußerst nützliches Werkzeug für die Verarbeitung natürlicher Sprache, aber in seiner ursprünglichen Form wurde er neben wiederkehrenden neuronalen Netzen verwendet. Die Innovation des Papers 2017 bestand als darin, RNNs vollständig zu vermeiden.
Was ist Selbstaufmerksamkeit?
Selbstaufmerksamkeit ist die wichtigste Komponente des Transformers. Mit der Selbstaufmerksamkeit werden die Metainformationen zu dem Wort, dem Satz, zur Information in eine logische Beziehung gesetzt. Die Sinnhaftigkeit eines Satzes und Wortes ergibt sich in der Regel aus seinem Zusammenhang.
Zwei Beispielsätze mit dem selben Wort, aber unterschiedlicher Bedeutung:
- „Hmm, das Essen ist lecker.“
- „Dem hängt der Lecker aber ordentlich raus!“
Das Wort „lecker“ hat zwei unterschiedliche Bedeutungen. Die Bedeutungen ergeben sich aus der impliziten Information, die sich aus den Sätzen ableiten lässt. Im ersten Satz deuten der Ausruf Hmm und das Hauptwort Essen auf eine Eigenschaft hin. Die Eigenschaft ist lecker und dafür gibt es in unserem Sprachgebrauch etliche Synonyme, wie gut schmecken. Der zweite Satz beschreibt etwas, was aktuell heraushängt. Die Bezeichnung Lecker deutet auch die mögliche Verwendung an. Etwas kann abgeleckt werden damit.
Selbstaufmerksamkeit hilft neuronalen Netzen den Kontext zu erkennen, Wörter hervorzuheben, Abhängigkeiten aufzulösen und vor allem semantische Rollen zu lernen.
Wenn sie noch immer nicht genug haben und noch mehr wissen wollen zu den drei Amigos – Positionierung, Aufmerksamkeit und Selbstaufmerksamkeit, dann empfehle ich ihnen:
http://jalammar.github.io/illustrated-transformer/
Wo werden Transformatoren eingesetzt?
BERT – bidirektionale Encoder Darstellung von Transformatoren – findet sich in fast jedem NLP Projekt. Eines der größten wird wohl die Google Suche selber sein.
BERT bezieht sich nicht nur auf eine Modellarchitektur, sondern auch auf ein geschultes Modell selber. Dieses Modell kann hier kostenlos heruntergeladen und verwendet werden. In BERT ist so ziemliche aller frei verfügbare Text eingeflossen. Das Aufgaben- und Anwendungsspektrum ist sehr groß damit, zum Beispiel:
- Textzusammenfassung
- Beantwortung von Fragen
- Klassifizierung
- Auflösung der benannten Entitäten
- Textähnlichkeit
- offensive Nachrichtenerkennung
- Verständnis von Benutzerabfragen
- ….
BERT beweist, dass man sehr gute Sprachmodelle erstellen kann, die mit undeklarierten Daten trainiert wurden, wie zum Beispiel Wikipedia Exzerpte, Reddit Inhalte, und dass diese große Basis Modell dann mit domainen-/anwendunsfallspezifischen Daten an viele verschiedene Anwendungsfälle angepasst werden kann.
In jüngerer Zeit hat das von OpenAI vorgestellte Modell GPT-3 die Menschen mit seiner Fähigkeit, automatisches Erstellen von realistischen Texten, verblüfft und schon des öfteren hinters Licht geführt. Chatbots können mit dieser Grundlage über so ziemliches jedes Thema sinngebende Gespräche führen.
Transformatoren kommen aber auch ausserhalb des NLP Bereichs zum Einsatz. Von der Komposition von Musik, Bilderstellung aus einer Textbeschreibung heraus, Kochrezepterstellung, bis hin zur bereits oben erwähnten Vorhersage von Proteinstrukturen.
Wie kann ich Transformatoren verwenden?
Nachdem ich ihnen die Leistungsfähigkeit vom Transformatoren verkauft habe wollen sie sicher wissen, wie sie diese selber verwenden können.
Das geht sehr einfach 😉
Sie können gängige Transformator basierte Modelle, wie BERT, von TensorFlow Hub herunterladen. Für ein Code Tutorial schauen sie sich dieses an.
Aber wenn sie wirklich ganz vorne dabei sein wollen und in Python ihren Code schreiben, dann empfehle ich ihnen die Transformers Bibliothek von der Firma HuggingFace. Auf Basis dieser Plattform können die beliebten NLP-Modelle, wie BERT, Roberta, T5, GPT-2 sehr entwicklerfreundlich trainiert und verwendet werden.
Vielen Dank für das Lesen bis zu diesem Punkt 😉